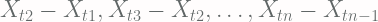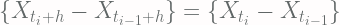Introduction
Here we do not show the derivation of Differential Chapman-Kolmogorov Equation, instead, we only show how to interpret the result. In the following sections, it is assumed that the stochastic process has Markov properties and the sample paths are always continuous and satisfy [Eq.1]:
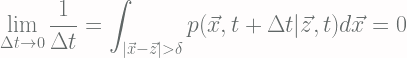
which practically says that integrating all possibility of changes of states z to x (i.e. the “distance”) that are greater than δ with δ > 0, the result probability is zero and, thus, there are no possibility that there are any changes of states within an infinitesimal period of time Δt. This is also called the Lindeberg condition.
Chapman-Kolomogov Equation
The Chapman-Kolomogov Equation defines, for a Markov Process, the conditional probabilities [Eq.2]:
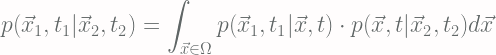
Differential Chapman-Kolomogov Equation
Assumptions
W.r.t that, we requires the following properties in order to reduce [Eq.2] into a differential equation for all δ > 0 and denote condition |x-z| < δ as ε:



In the first requirement, W(z, t) is the jump term which describe discontinuous evolution for all +ve non-zero distance between x and z. Note that if W = 0, we restore [Eq.1] and the sample path is continuous.
In the second requirement, if δ limit to zero, the O(δ) term vanishes (i.e. continuous path), and the term A_i is often called the drift term because it suggest that E[dx] = A(x, t)dt, which can be interpret as the instantaneous rate of change of z..
In the third requirement, B(z, t) is often referred as the diffusion term, which can be seen as the instantaneous rate of change of covariance of all process close to z.
Derivation
The full derivation will not be stated here, in fact it can be easily found on the internet by search the key words Differential Chapman-Kolmogorov. However, it is crucial to understand the origin of it and a brief introduction to the origin of differential Chapman-Kolmogorov equation will be written below referencing Crispin Gardiner’s book Stochastic methods: a handbook for the natural and social sciences.
First, we consider the time evolution of certain function f(z) which we required it to be twice differentiable. Then the instantaneous rate of change of expected value of this function can be written as:

[by first principle]
![\displaystyle = \lim_{\Delta t \rightarrow 0} \left[ \frac{1}{\Delta t} \int_{\vec{x} \in \Omega} d\vec{x} \left\{ f(\vec{x}) \Big[p(\vec{x}, t+\Delta t|\vec{y}, t') - p(\vec{x}, t|\vec{y}, t') \Big] \right\} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Clim_%7B%5CDelta+t+%5Crightarrow+0%7D+%5Cleft%5B+%5Cfrac%7B1%7D%7B%5CDelta+t%7D+%5Cint_%7B%5Cvec%7Bx%7D+%5Cin+%5COmega%7D+d%5Cvec%7Bx%7D+%5Cleft%5C%7B+f%28%5Cvec%7Bx%7D%29+%5CBig%5Bp%28%5Cvec%7Bx%7D%2C+t%2B%5CDelta+t%7C%5Cvec%7By%7D%2C+t%27%29+-+p%28%5Cvec%7Bx%7D%2C+t%7C%5Cvec%7By%7D%2C+t%27%29+%5CBig%5D+%5Cright%5C%7D+%5Cright%5D+&bg=fffdfd&fg=606666&s=2&c=20201002)
[by Chapman-Kolmogorov Equation]
![\displaystyle = \lim_{\Delta t \rightarrow 0} \left[ \frac{1}{\Delta t} \int d\vec{x} \int d\vec{z} \left\{ f(\vec{x}) \Big[ p(\vec{x}, t+\Delta t|\vec{z}, t)p(\vec{z}, t|\vec{y}, t') - f(\vec{z})p(\vec{z}, t|\vec{y}, t') \Big] \right\} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Clim_%7B%5CDelta+t+%5Crightarrow+0%7D+%5Cleft%5B+%5Cfrac%7B1%7D%7B%5CDelta+t%7D+%5Cint+d%5Cvec%7Bx%7D+%5Cint+d%5Cvec%7Bz%7D+%5Cleft%5C%7B+f%28%5Cvec%7Bx%7D%29+%5CBig%5B+p%28%5Cvec%7Bx%7D%2C+t%2B%5CDelta+t%7C%5Cvec%7Bz%7D%2C+t%29p%28%5Cvec%7Bz%7D%2C+t%7C%5Cvec%7By%7D%2C+t%27%29+-+f%28%5Cvec%7Bz%7D%29p%28%5Cvec%7Bz%7D%2C+t%7C%5Cvec%7By%7D%2C+t%27%29+%5CBig%5D+%5Cright%5C%7D+%5Cright%5D+&bg=fffdfd&fg=606666&s=2&c=20201002)
Divide the integrals into two regions |x-z| > δ and |x-z| < δ and some manipulation, the result will be [Eq.3]:
![\displaystyle \frac{\partial p(\vec{z}, t|\vec{y}, t')}{\partial t} = - \sum_i \frac{\partial}{\partial z_i} \big[ A_i(\vec{z}, t)p(\vec{z}, t|\vec{y}, t') \big] + \frac{1}{2} \sum_{i, j} \frac{\partial^2}{\partial z_i \partial z_j}\Big[B_{ij}(\vec{z}, t)p(\vec{z}, t|\vec{y}, t')\Big] \\ \indent + \int_{\vec{x} \in \Omega} \Big[ W(\vec{z}|\vec{x}, t)p(\vec{x}, t|\vec{y}, t') - W(\vec{x}|\vec{z}, t)p(\vec{z}, t|\vec{y}, t') \Big] d\vec{x}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B%5Cpartial+p%28%5Cvec%7Bz%7D%2C+t%7C%5Cvec%7By%7D%2C+t%27%29%7D%7B%5Cpartial+t%7D+%3D+-+%5Csum_i+%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+z_i%7D+%5Cbig%5B+A_i%28%5Cvec%7Bz%7D%2C+t%29p%28%5Cvec%7Bz%7D%2C+t%7C%5Cvec%7By%7D%2C%C2%A0+t%27%29+%5Cbig%5D+%2B+%5Cfrac%7B1%7D%7B2%7D+%5Csum_%7Bi%2C+j%7D+%5Cfrac%7B%5Cpartial%5E2%7D%7B%5Cpartial+z_i+%5Cpartial+z_j%7D%5CBig%5BB_%7Bij%7D%28%5Cvec%7Bz%7D%2C+t%29p%28%5Cvec%7Bz%7D%2C+t%7C%5Cvec%7By%7D%2C+t%27%29%5CBig%5D+%5C%5C+%5Cindent+%2B+%5Cint_%7B%5Cvec%7Bx%7D+%5Cin+%5COmega%7D+%5CBig%5B+W%28%5Cvec%7Bz%7D%7C%5Cvec%7Bx%7D%2C+t%29p%28%5Cvec%7Bx%7D%2C+t%7C%5Cvec%7By%7D%2C+t%27%29+-+W%28%5Cvec%7Bx%7D%7C%5Cvec%7Bz%7D%2C+t%29p%28%5Cvec%7Bz%7D%2C+t%7C%5Cvec%7By%7D%2C+t%27%29+%5CBig%5D+d%5Cvec%7Bx%7D%C2%A0+&bg=fffdfd&fg=606666&s=2&c=20201002)
this is the differential Chapman-Kolmogorov equation or sometimes called the master equation
Interpreting the equation
Discontinuous jumps
If we deliberately force the master equation to disobey [Eq.1], we will obtain a discontinuous process. For example, forcing both A(z, t) and B(z, t) to be zero, the differential equation is left to be:
![\displaystyle \frac{\partial}{\partial t} p(\vec{z}, t|\vec{y}, t') = \int_{\vec{x} \in \Omega} d\vec{x} \Big[ W(\vec{z}|\vec{x}, t) p(\vec{x}, t|\vec{y}, t') - W(\vec{x}|\vec{z}, t)p(\vec{z}, t|\vec{y}, t')\Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+t%7D+p%28%5Cvec%7Bz%7D%2C+t%7C%5Cvec%7By%7D%2C+t%27%29+%3D+%5Cint_%7B%5Cvec%7Bx%7D+%5Cin+%5COmega%7D+d%5Cvec%7Bx%7D+%5CBig%5B+W%28%5Cvec%7Bz%7D%7C%5Cvec%7Bx%7D%2C+t%29+p%28%5Cvec%7Bx%7D%2C+t%7C%5Cvec%7By%7D%2C+t%27%29+-+W%28%5Cvec%7Bx%7D%7C%5Cvec%7Bz%7D%2C+t%29p%28%5Cvec%7Bz%7D%2C+t%7C%5Cvec%7By%7D%2C+t%27%29%5CBig%5D+&bg=fffdfd&fg=606666&s=2&c=20201002)
Using initial condition 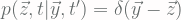

![\displaystyle = \delta(\vec{y} - \vec{z})\Big[ 1 - \int_{\vec{x} \in \Omega} W(\vec{x}|\vec{y}, t)\Delta t d\vec{x}\Big] + W(\vec{z}|\vec{y}, t)\Delta t](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cdelta%28%5Cvec%7By%7D+-+%5Cvec%7Bz%7D%29%5CBig%5B+1+-+%5Cint_%7B%5Cvec%7Bx%7D+%5Cin+%5COmega%7D+W%28%5Cvec%7Bx%7D%7C%5Cvec%7By%7D%2C+t%29%5CDelta+t+d%5Cvec%7Bx%7D%5CBig%5D+%2B+W%28%5Cvec%7Bz%7D%7C%5Cvec%7By%7D%2C+t%29%5CDelta+t+&bg=fffdfd&fg=606666&s=2&c=20201002)
see that if we want to know the probability of staying in y after Δt, we substitute z as y and get the following equation [Eq.4]
![\displaystyle p(\vec{y}, t+\Delta t)|\vec{y}, t) = 1\Big[ 1-\int_{\vec{x} \in \Omega} W(\vec{x}|\vec{y}, t)\Delta t d\vec{x} \Big] + W(\vec{y}|\vec{y}, t)\Delta t](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p%28%5Cvec%7By%7D%2C+t%2B%5CDelta+t%29%7C%5Cvec%7By%7D%2C+t%29+%3D+1%5CBig%5B+1-%5Cint_%7B%5Cvec%7Bx%7D+%5Cin+%5COmega%7D+W%28%5Cvec%7Bx%7D%7C%5Cvec%7By%7D%2C+t%29%5CDelta+t+d%5Cvec%7Bx%7D+%5CBig%5D+%2B+W%28%5Cvec%7By%7D%7C%5Cvec%7By%7D%2C+t%29%5CDelta+t%C2%A0+&bg=fffdfd&fg=606666&s=2&c=20201002)
Let’s break this down terms by terms so that it is easier to understand. Firstly, W(z|y, t) is the instantaneous probability (or probability per time) of going to state z from y, therefore, W(z|y, t)Δt is the accumulated probability of going to z from y within time period Δt. Secondly, the integral inside the square bracket denotes the total probability of leaving state y and going to any other states x, thus, one minus the integral is the total probability of staying in state y. In the case of [Eq.4], W(y|y, t)Δt is the probability of going from state y to state y meaning it includes the probability of first leaving state y then go back to y within Δt, and the integral represents ONLY staying in state y. Finally, the sum of both terms converge to the probability of staying in state y within Δt in [Eq.4].
Fokker-Planck Equation
The Fokker-Planck Equation is obtained when forcing the Jump term W in the master equation to become zero [Eq.5]
![\displaystyle \frac{\partial p(\vec{z}, t|\vec{y}, t')}{\partial t} = - \sum_i \frac{\partial}{\partial z_i} \big[ A_i(\vec{z}, t)p(\vec{z}, t|\vec{y}, t') \big] + \frac{1}{2} \sum_{i, j} \frac{\partial^2}{\partial z_i \partial z_j}\Big[B_{ij}(\vec{z}, t)p(\vec{z}, t|\vec{y}, t')\Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B%5Cpartial+p%28%5Cvec%7Bz%7D%2C+t%7C%5Cvec%7By%7D%2C+t%27%29%7D%7B%5Cpartial+t%7D+%3D+-+%5Csum_i+%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+z_i%7D+%5Cbig%5B+A_i%28%5Cvec%7Bz%7D%2C+t%29p%28%5Cvec%7Bz%7D%2C+t%7C%5Cvec%7By%7D%2C%C2%A0+t%27%29+%5Cbig%5D+%2B+%5Cfrac%7B1%7D%7B2%7D+%5Csum_%7Bi%2C+j%7D+%5Cfrac%7B%5Cpartial%5E2%7D%7B%5Cpartial+z_i+%5Cpartial+z_j%7D%5CBig%5BB_%7Bij%7D%28%5Cvec%7Bz%7D%2C+t%29p%28%5Cvec%7Bz%7D%2C+t%7C%5Cvec%7By%7D%2C+t%27%29%5CBig%5D%C2%A0%C2%A0+&bg=fffdfd&fg=606666&s=2&c=20201002)
This equation is sometimes know as the diffusion process with drift term A and diffusion matrix B. Based on this equation, if we wish to compute 
![\displaystyle \frac{\partial p(\vec{z}, t|\vec{y}, t')}{\partial t} = - \sum_i A_i(\vec{z}, t)\frac{\partial}{\partial z_i} \big[ p(\vec{z}, t|\vec{y}, t') \big] + \frac{1}{2} \sum_{i, j} B_{ij}(\vec{z}, t) \frac{\partial^2}{\partial z_i \partial z_j}\Big[p(\vec{z}, t|\vec{y}, t')\Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B%5Cpartial+p%28%5Cvec%7Bz%7D%2C+t%7C%5Cvec%7By%7D%2C+t%27%29%7D%7B%5Cpartial+t%7D+%3D+-+%5Csum_i+A_i%28%5Cvec%7Bz%7D%2C+t%29%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+z_i%7D+%5Cbig%5B+p%28%5Cvec%7Bz%7D%2C+t%7C%5Cvec%7By%7D%2C%C2%A0+t%27%29+%5Cbig%5D+%2B+%5Cfrac%7B1%7D%7B2%7D+%5Csum_%7Bi%2C+j%7D+B_%7Bij%7D%28%5Cvec%7Bz%7D%2C+t%29+%5Cfrac%7B%5Cpartial%5E2%7D%7B%5Cpartial+z_i+%5Cpartial+z_j%7D%5CBig%5Bp%28%5Cvec%7Bz%7D%2C+t%7C%5Cvec%7By%7D%2C+t%27%29%5CBig%5D%C2%A0%C2%A0+&bg=fffdfd&fg=606666&s=2&c=20201002)
and solve this equation with the constrain 
![\displaystyle p(\vec{z}, t+\Delta t|\vec{y}, t) = \sqrt{\Big[(2\pi)^N \text{det}(B(\vec{y}, t)\Delta t) \Big]}^{-1} \cdot \\ \indent \exp \bigg[ -\frac{1}{2\Delta t} [\vec{z}-\vec{y}-A(\vec{y}, t)\Delta t]^T B(\vec{y}, t)^{-1} [\vec{z} - \vec{y} - A(\vec{y}, t)\Delta t]\bigg]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p%28%5Cvec%7Bz%7D%2C+t%2B%5CDelta+t%7C%5Cvec%7By%7D%2C+t%29+%3D+%5Csqrt%7B%5CBig%5B%282%5Cpi%29%5EN+%5Ctext%7Bdet%7D%28B%28%5Cvec%7By%7D%2C+t%29%5CDelta+t%29+%5CBig%5D%7D%5E%7B-1%7D+%5Ccdot+%5C%5C+%5Cindent+%5Cexp+%5Cbigg%5B+-%5Cfrac%7B1%7D%7B2%5CDelta+t%7D+%5B%5Cvec%7Bz%7D-%5Cvec%7By%7D-A%28%5Cvec%7By%7D%2C+t%29%5CDelta+t%5D%5ET+B%28%5Cvec%7By%7D%2C+t%29%5E%7B-1%7D+%5B%5Cvec%7Bz%7D+-+%5Cvec%7By%7D+-+A%28%5Cvec%7By%7D%2C+t%29%5CDelta+t%5D%5Cbigg%5D+&bg=fffdfd&fg=606666&s=1&c=20201002)
which is, in fact, a Gaussian distribution with variance as matrix 
Reference
Crispin W.. Gardiner. Stochastic methods: a handbook for the natural and social sciences. Springer, 2009.
Hierro, Juan, and César Dopazo. “Singular boundaries in the forward Chapman-Kolmogorov differential equation.” Journal of Statistical Physics 137.2 (2009): 305-329.
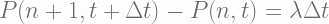
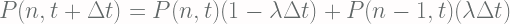
![\displaystyle \frac{\partial P(n, t)}{\partial t} = \frac{P(n, t+\Delta t) - P(n, t)}{\Delta t} = \lambda \left[P(n- 1, t) - P(n, t)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B%5Cpartial+P%28n%2C+t%29%7D%7B%5Cpartial+t%7D+%3D+%5Cfrac%7BP%28n%2C+t%2B%5CDelta+t%29+-+P%28n%2C+t%29%7D%7B%5CDelta+t%7D+%3D+%5Clambda+%5Cleft%5BP%28n-+1%2C+t%29+-+P%28n%2C+t%29%5Cright%5D+&bg=fffdfd&fg=606666&s=2&c=20201002)

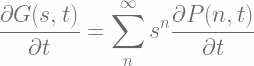
![\displaystyle = \lambda \sum_{n=0}^{\infty} s^n \left[P(n-1, t) - P(n, t)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Clambda+%5Csum_%7Bn%3D0%7D%5E%7B%5Cinfty%7D+s%5En+%5Cleft%5BP%28n-1%2C+t%29+-+P%28n%2C+t%29%5Cright%5D+&bg=fffdfd&fg=606666&s=2&c=20201002)


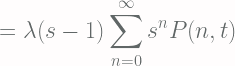
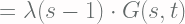
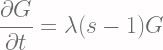
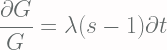
![\displaystyle \ln{[G(s, t)]} = \lambda t(s-1) + C](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cln%7B%5BG%28s%2C+t%29%5D%7D+%3D+%5Clambda+t%28s-1%29+%2B+C+&bg=fffdfd&fg=606666&s=2&c=20201002)
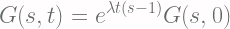
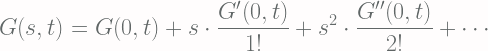

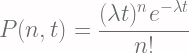
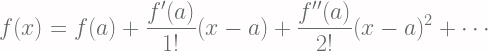

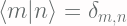
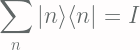

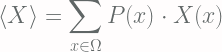
![\displaystyle \left< f[X(x)] \right> = \int_{\Omega} f[X(x)] P(x) dx](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%3C+f%5BX%28x%29%5D+%5Cright%3E+%3D+%5Cint_%7B%5COmega%7D+f%5BX%28x%29%5D+P%28x%29+dx+&bg=fffdfd&fg=606666&s=2&c=20201002)

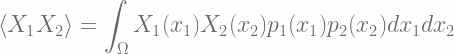
![\displaystyle \text{var}[X] = \left<[X-\left<X\right>]^2\right>](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctext%7Bvar%7D%5BX%5D+%3D+%5Cleft%3C%5BX-%5Cleft%3CX%5Cright%3E%5D%5E2%5Cright%3E+&bg=fffdfd&fg=606666&s=2&c=20201002)
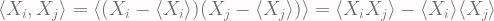

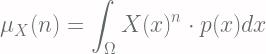
![\displaystyle \overline{\mu}_X (n) = \left<[X-\left<X\right>]^n\right>](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Coverline%7B%5Cmu%7D_X+%28n%29+%3D+%5Cleft%3C%5BX-%5Cleft%3CX%5Cright%3E%5D%5En%5Cright%3E+&bg=fffdfd&fg=606666&s=2&c=20201002)
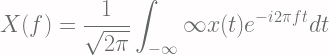




 where x is the position and t is time.
where x is the position and t is time.

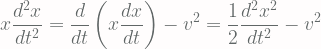

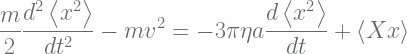
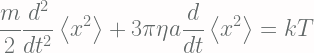


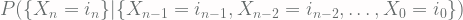
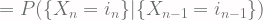
 ,
,




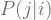 as
as 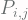 )
)
 .
.



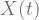 , it is identified as a Poisson process if it satisfy the following conditions:
, it is identified as a Poisson process if it satisfy the following conditions: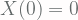
![P(X(t)=k) = [(\lambda t)^k e^{-\lambda t}]/k!](https://s0.wp.com/latex.php?latex=P%28X%28t%29%3Dk%29+%3D+%5B%28%5Clambda+t%29%5Ek+e%5E%7B-%5Clambda+t%7D%5D%2Fk%21+&bg=fffdfd&fg=606666&s=1&c=20201002)
 can be formulated as follow [Eq.1]:
can be formulated as follow [Eq.1]:








 = A set of random variables denoting the change in x-coordinates of each particle
= A set of random variables denoting the change in x-coordinates of each particle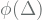 = Probability density function of each random variables
= Probability density function of each random variables  , note that this is an even function
, note that this is an even function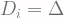 into account. We therefore have [Eq.1]:
into account. We therefore have [Eq.1]:

![\displaystyle f(x + \Delta, t) \\ \indent = f(x, t) + [x + \Delta - x]\cdot \frac{\partial f}{\partial x} + \frac{[x + \Delta - x]^2}{2!}\cdot\frac{\partial^2 f}{\partial x^2} + \cdots \\ \indent = f(x, t) + \Delta\cdot \frac{\partial f}{\partial x} + \frac{\Delta^2}{2!}\cdot\frac{\partial^2 f}{\partial x^2} + \cdots](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+f%28x+%2B+%5CDelta%2C+t%29+%5C%5C+%5Cindent+%3D+f%28x%2C+t%29+%2B+%5Bx+%2B+%5CDelta+-+x%5D%5Ccdot+%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+x%7D+%2B+%5Cfrac%7B%5Bx+%2B+%5CDelta+-+x%5D%5E2%7D%7B2%21%7D%5Ccdot%5Cfrac%7B%5Cpartial%5E2+f%7D%7B%5Cpartial+x%5E2%7D+%2B+%5Ccdots+%5C%5C+%5Cindent+%3D+f%28x%2C+t%29+%2B+%5CDelta%5Ccdot+%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+x%7D+%2B+%5Cfrac%7B%5CDelta%5E2%7D%7B2%21%7D%5Ccdot%5Cfrac%7B%5Cpartial%5E2+f%7D%7B%5Cpartial+x%5E2%7D+%2B+%5Ccdots+&bg=fffdfd&fg=606666&s=1&c=20201002)
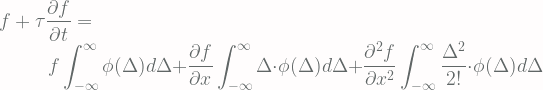


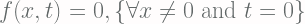 and
and 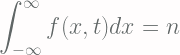

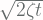
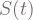 within period
within period 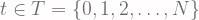 in sample space
in sample space  , with discrete stochastic process
, with discrete stochastic process  called steps of the random walk with the constrain
called steps of the random walk with the constrain 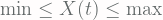 .
.
 represents the initial value or start point of the random walk. Also, select that each elements of
represents the initial value or start point of the random walk. Also, select that each elements of 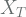 can take on integer values between -5 and 5.
can take on integer values between -5 and 5. .
.

 to follows
to follows  . It is, however, possible to introduce various other constrain to the process w.r.t. the application of your application.
. It is, however, possible to introduce various other constrain to the process w.r.t. the application of your application.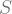 and
and 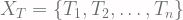 fulfills the definition of stochastic process with the state space being different.
fulfills the definition of stochastic process with the state space being different. such that
such that  then
then